论文解读--Taking A Closer Look at Domain Shift: Category-level Adversaries for Semantics Consistent Domain Adaptation
0 说明
- 由于毕业设计需要,进行相关论文的学习
- 论文解读第一篇: Taking A Closer Look at Domain Shift: Category-level Adversaries for Semantics Consistent Domain Adaptation
1 研究背景
- 基于深度学习的语义分割方法是以像素级的人工标注为代价进行监督训练的,费时费力;借助计算机虚拟图像技术,几乎无成本地获得无限量自动标注数据,但虚拟图像和现实图像间存在严重的数据差异(域迁移),进而导致了训练的模型在真实图像上效果较差。
- 如下图所示,在图的第一行有虚拟图像训练得到的全卷积网络(FCN)在虚拟图像数据集上分割效果较好,但是当相同的网络模型迁移到真实数据(Cityscapes数据集)上之后,可以看出分割结果较差。
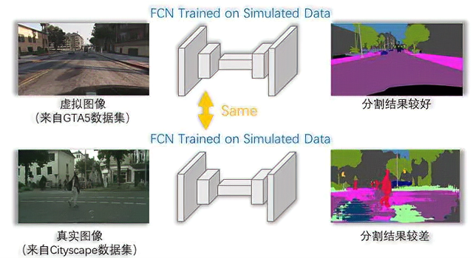
- 总结来说就是就是 1)像素级人工标注的代价和 2)域迁移的影响。
2 研究问题
- 全局体征分布、负迁移。
- 针对域迁移问题,常规的策略是通过对抗学习来调整源域Source与目标域Target之间的分布特征,但是这种全局特征分布(Marginal Distribution)对齐的策略,会产生语义不一致即负迁移(Negative Transfer)的问题。如下图所示:
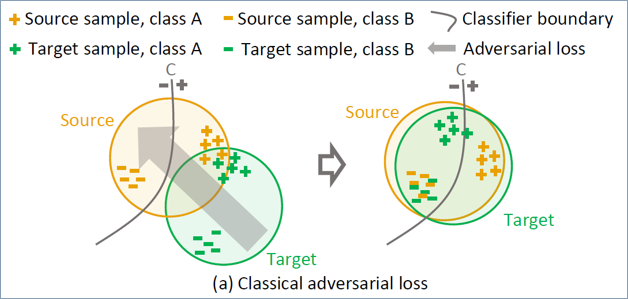
- 橙色区域表示源域,绿色区域表示目标域,“+”和“-”号表示特征分布,曲线表示分类边界,灰色箭头大小表示损失的大小。由于对抗损失作用于全局特征,原先分类良好的“+”类别特征为了迎合全局对齐,会被映射到源域中的其他类别,导致语义不一致。
- 举例来说,目标域中汽车这一类,假设源域中车辆的特征是接近的,因此,在没有经过域适应算法之前,目标域汽车类也能够正确分割;然而,为了迎合全局特征对齐,目标域中的汽车类特征反而可能被错误映射到源域中的其他类别。
3 创新点
3.1 传统方法
传统方法广泛使用的是:在网络中加入一个域判别器Discriminator(D),利用对抗训练机制,减少源域、目标域的不同分布差异,加强原始网络G在域间的泛化能力:
- (1) 利用源域的有标签数据进行有监督学
其中$X_S$、$Y_S$为源数据及其对应标签,$G$为生成网络,即生成器损失为$X_S$通过网络$G$后与$Y_S$的损失的数学期望。
- (2) 通过对抗学习,降低域判别器D的精度,对齐源域与目标域的特征分布
其中$X_T$为目标域数据,无标签。
3.2 创新
语义级对抗学习域适应方法:
- 在传统的对抗学习框架基础之上加入了协同训练的思想,加入了两个互斥的分类器。
- 自适应对抗损失权重实现
- 当两个分类器预测一致时,该特征语义一致性较好,减少全局对齐策略对这些特征的影响;
- 反之,需要使用对抗损失,加大对齐力度进行特征对齐。
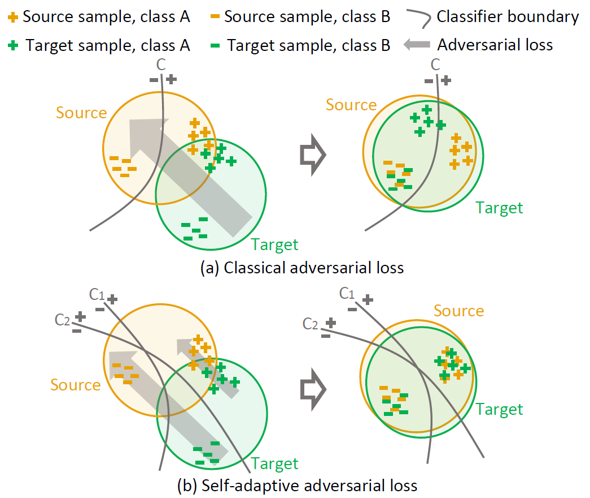
如上图所示,图(a)在第2节已经了解过,图(b)为自适应对抗损失示意图。使用了两个互斥的分类器,有两个曲线(分别边界线)。
可以看出,经过创新改进,判断出类别“+”起初便对齐较好,于是对抗损失较小,而类别“-”由于对齐较差,其对抗损失较差,进而起到了保护原来对齐较好特征不受影响,又促进对齐较差的特征对齐。
4 方法总结
论文中提出于一级对抗网络(Category-Level Adversarial Network,CLAN)
4.1 网络结构
语义级对抗网络由三部分组成:特征提取E、分类器C和判别器D,前两部分组成生成器G。
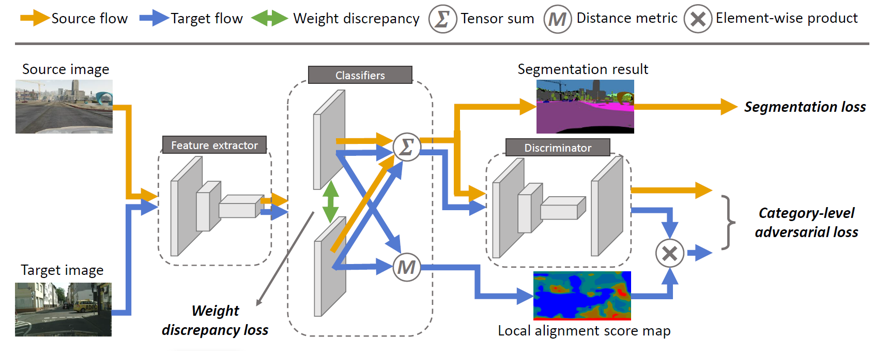
橙色线表示源域流,蓝色线表示目标域流。
- 其中两个互斥的分类器用于判断目标域的隐层特征是否已经达到局部对齐,在后续对抗训练时,网络依据互斥分了器产生的两个预测向量之差来判别网络所受反馈的对抗损失进行加权。
- 绿色箭头处使用余弦距离作为分类器损失,训练两个分类器预测产生不同的模型参数。
- 源域流通过两个互斥的分类器产生的预测作为源域的集成预测,一方面被标签监督产生分割损失,另一方面进入判别器D,作为源域样本。
- 目标域流同样由分类器产生的集成损失进入判别器,同时,求得两个分类器的预测差值,作为局部对齐程度的依据(local alignment score map),该距离与D所反馈的损失相乘得到语义级别的对抗损失。
4.2 损失函数
模型损失函数
训练目标,交替优化G和D,直至总损失收敛为止。
- 分割损失:若给定形状为$3\times H \times W$的图像和形状为$C \times H \times W$的标签图,其中$C$是语义类别的数量
其中,$p_{ic}$ 表示像素$i$为$C$类的概率,$y_{ic}$表示像素$i$为$C$类的真值(1 or 0)。
即分类器对各个像素分类预测值的负对数与真值的乘积的累加和。
- 分类器损失:
即两个分类器网络中参数的余弦距离。
- 对抗损失:
其中,$𝑀(𝑝^{(1)},𝑝^{(2)})$表示两个分类器输出向量的余弦距离。
即在传统对抗损失上加权了由两个分类器的预测差异权重。
5 实验总结
5.1 语义分割可视化
- CLAN与传统对抗网络(TAN)的对比
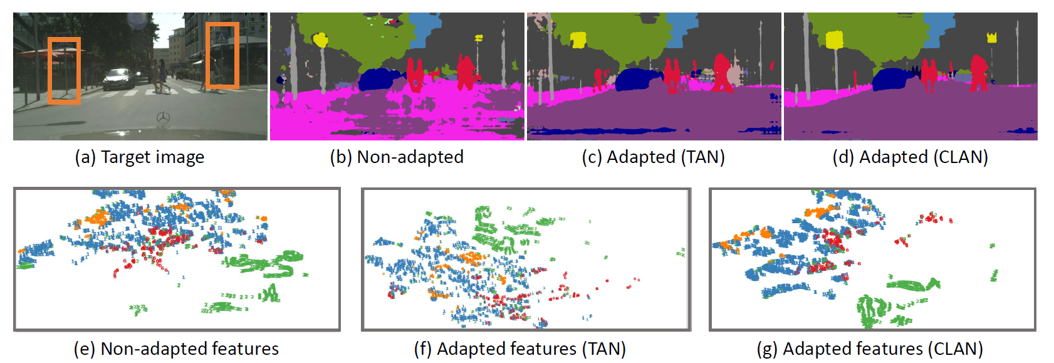
重点关注橙色框中的电线杆和交通标志。
图(e、f、g)为高维特征通过非线性降维算法(t-SNE)到二维空间(仅显示4个相关类,即建筑物为蓝色、交通标志为橙色、杆子为灰色、植被为绿色)
- 上图表明,有些类别特征在没有进行域迁移之前,就已经是对齐的。传统的全局域适应方法反而会破坏这种语义一致性,造成域迁移;而本文提出的语义级对抗网络降低了全局对齐对这些类的影响。
- 特征簇中心距离
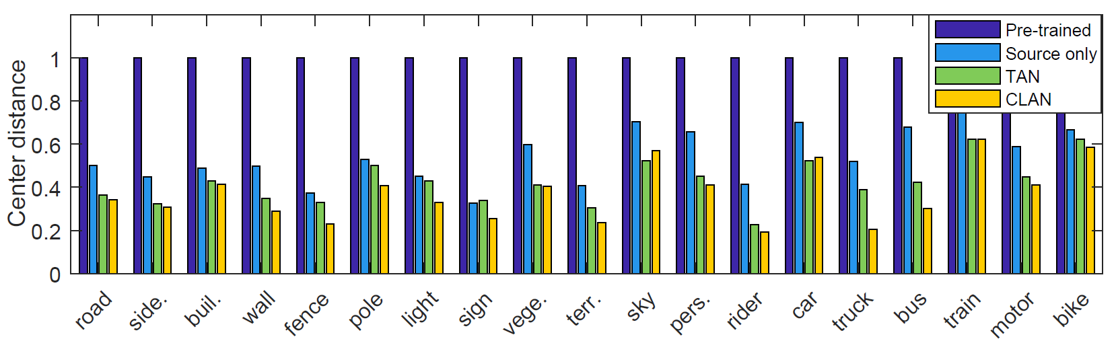
上图展示隐层隐层空间源域与目标域之间同语义特征簇的中心距离,该距离越小,说明两个域之间的语义对齐越好。
- 分割效果

各列为:目标域图、无自适应分割效果、CLAN分割效果、标准效果图。
5.2 总结
- 论文提出的语义级对抗学习域适应网络(CLAN),使用协同训练结合对抗学习的设计,旨在解决无监督域自适应(UDA)语义分割中,由全局特征对齐所引起的语义不一致问题,有效地防止了负迁移。
- 在两个域适应语义分割任务,即GTA5 -> Cityscapes 和 SYNTHIA -> Cityscapes 上进行了实验验证,以及实际的语义分割效果中都取得了较好的实验结果。具有良好的应用前景。
6 相关链接
 wechat
wechat alipay
alipay